Overview:
-
The K-means clustering method divides a set of points in an n-dimensional space into multiple groups called clusters, which are centred around certain points called centroids.
-
The grouping is done based on the proximity of the data points to the centroid. Initially these centroids are chosen randomly or given initial values.
-
Subsequently, the Euclidean distance between each point to each centroid is calculated. For a point p1, d1 and d2 are distances to centroids c1 and c2. Among d1 and d2, if d1 is smaller then p1 is assigned to the cluster g1. If d2 is smaller then the point p1 is assigned to the cluster g2.
-
During the next iteration the means of the points in each cluster are calculated and assigned as new centroids. The process is repeated until there is no significant change in the centroids between two iterations.
-
K-means clustering is an unsupervised learning technique. In unsupervised learning technique, the data is not tagged/labelled. There are no predefined groups. The k-means algorithm divides similar data into multiple groups called clusters using centroids.
-
The other unsupervised learning techniques include dimension reduction, association rules and other clustering methods like hierarchical clustering and gaussian mixture models.
K-means clustering using SciPy:
-
The function kmeans() from the scipy.vq module of the SciPy library provides an implementation of the k-means clustering algorithm.
-
Using parameter k_or_guess, a given number of random points from the data can be chosen as initial centroids or specific centroids can be passed.
-
Using the optional parameter iter, the number of iterations can be specified after which the function returns the final centroids.
-
Instead of specifying the number of iterations, the threshold of the distortion (mean value of the distances from points to centroids) can be specified using the optional parameter threshold.
-
To get the exact centroids during next run of the program the optional, parameter rng can be used for specifying a random seed.
Applications of k-means clustering:
-
K-means clustering is used in medical imaging for diagnosis of various disease conditions using CT, MRI and other modalities.
-
Outliers in each cluster can be easily found using K-means clustering including the extreme among them. Hence K-means clustering is often used in anomaly detection applciations.
Example:
|
# Example Python program that creates clusters # Data courtesy - data collected from the following sources: import numpy as np livingBeings = ["Bald eagle", "Green winged amazon Parrot", features = np.array([[5, 0.011987], [0.5, 0.01365], [0.45, 0.00725], # Create six centroids print("Distortion:") #print(features[:, 0], features[0:,1]) figr = plt.figure() # Mark the centroids hence creating clusters # Set logrithmic scale # Label the graph # Annotate the data points plt.show() |
Output:
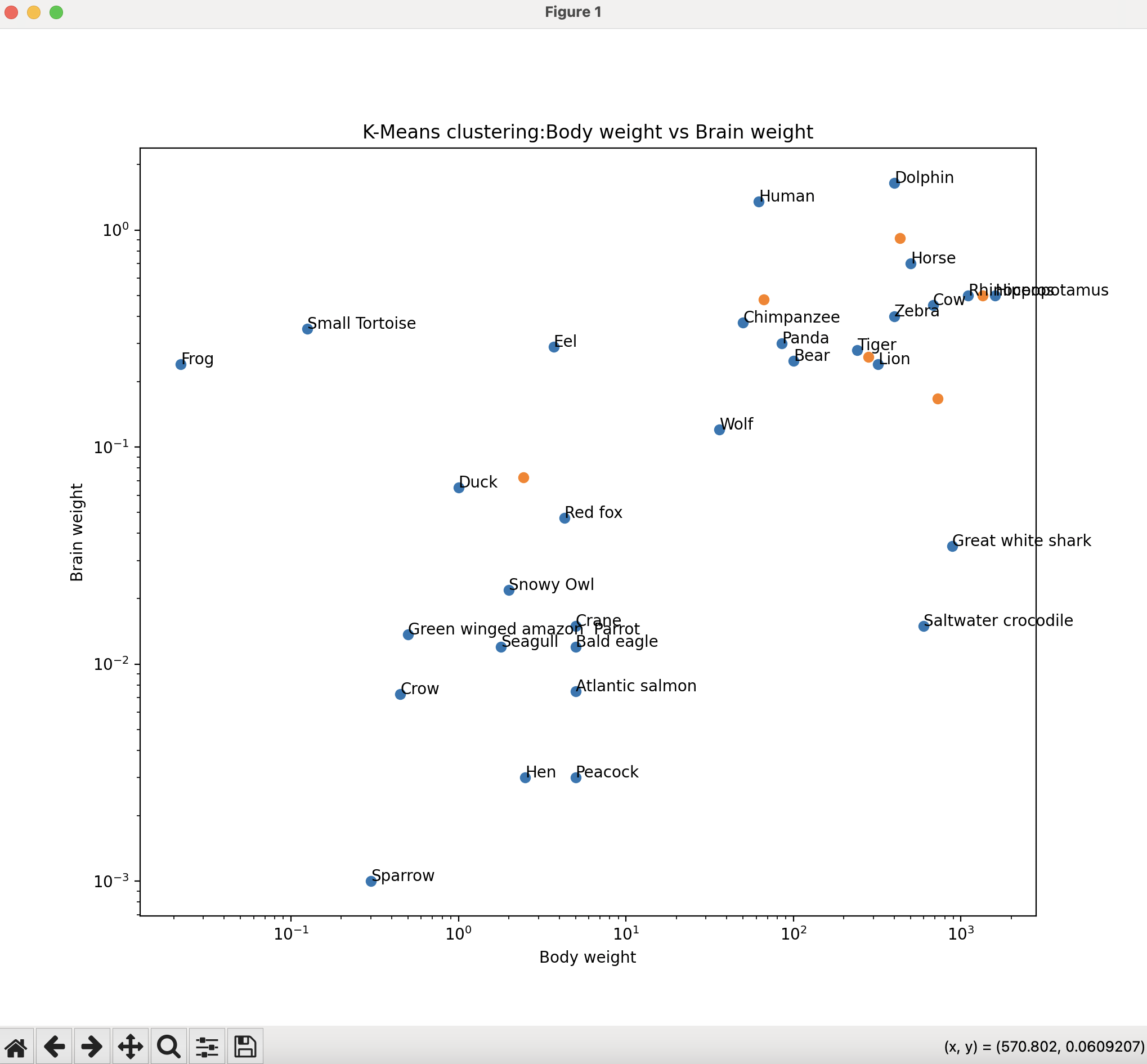
|
Centroids: |